Last time, I wrote about how to parse HTML and convert it to NSAttributedStrings quickly. Unfortunately, in the time since then, it’s gotten slower. It’s still a good deal faster than it was before all that work, mind you. At fault is not any of the optimizations I discussed last time, fortunately. Rather, to get the correct behavior across a whole slew of edge cases, there was more work that needed to be done.
The root of all this complexity is the fact that I’m essentially trying to replicate a portion of the CSS layout algorithm using only the information provided by the HTML tokenization process (that is, the text that is emitted and the start/end tags) while flattening into a single string all the structure used to achieve those results.
The previous version of this—which did correctly handle the initial test cases that I threw at it, but not what cropped up in the wild—worked by trying to keep track of when you had just finished one block element and then, before starting a new one, emitting line breaks to approximate the spacing between them that would otherwise be specified by CSS. Here are an assortment of issues that arise when using this strategy with real input:
Blocks can start after a closing non-block element
<span>a</span><p>b</p>
This should render equivalent to two blocks, the first containing “a” and the second containing “b”.
Blocks can start immediately after a character
a<p>b</p>
This should render the same as the example above.
Whitespace between blocks should be ignored
That is, this:
<p>a</p><p>b</p>
should render equivalent to this:
<p>a</p>
<p>b</p>
which in turn should render equivalent to this:
<p>a</p>
<p>b</p>
So you need to keep track of the whitespace that was emitted between two block elements, and not emit any extra—or possibly remove some.
Whitespace within blocks should not be ignored
But you can’t ignore whitespace (or even just newlines) altogether, because there is content that expects newlines to be preserved. And, moreover, people will do things like writing code—where they expect whitespace to be preserved—outside of a <pre> context.
Empty block elements shouldn’t take up space
<p>a</p>
<p></p>
<p>b</p>
This should render equivalently to the examples above with two <div>s, since the emtpy tag shouldn’t consume any space. Additionally, other empty elements inside that middle <div> shouldn’t cause it to start consuming space either.
A line break tag at the end of a block should be ignored
So while this example should appear to have three line breaks between “a” and “b”:
<p>a</p>
<p><br>b</p>
this next example should only appear to have two:
<p>a<br></p>
<p>b</p>
But a line break tag at the beginning of a block should take up space
This example should have about three lines worth of space between “a” and “b”. One for the space between “a” and the middle paragraph, one for the <br> content of the middle paragraph, and one for the space between the middle paragraph and “b”.
<p>a</p>
<p><br></p>
<p>b</p>
Actual newline characters should be ignored at the beginning and end of blocks
So all three of these paragraphs are equivalent:
<p>a</p>
<p>a
</p>
<p>
a</p>
Leading whitespace in <pre> is ignored
Presumably because, when authoring HTML, you’re expected to write the opening tag on one line and then start your content on the next.
Observationally, this also appears to be the case for whitespace preceding </pre>, but the HTML spec is silent on the matter.
List items are like blocks but with only one linebreak
In this case, there should be no blank lines between “a” and “b”:
<ul>
<li>a</li>
<li>b</li>
</ul>
Blocks in <li> should not produce line breaks at the beginning/end of the list item
It’s perfectly okay to have block elements inside list items, but the following should render the same as the previous example:
<ul>
<li><p>a</p></li>
<li><p>b</p></li>
</ul>
But two blocks within the same <li> should have a blank line separating them
<ul>
<li><p>a</p><p>b</p></li>
</ul>
Okay, I’m going insane. How do you fix it?
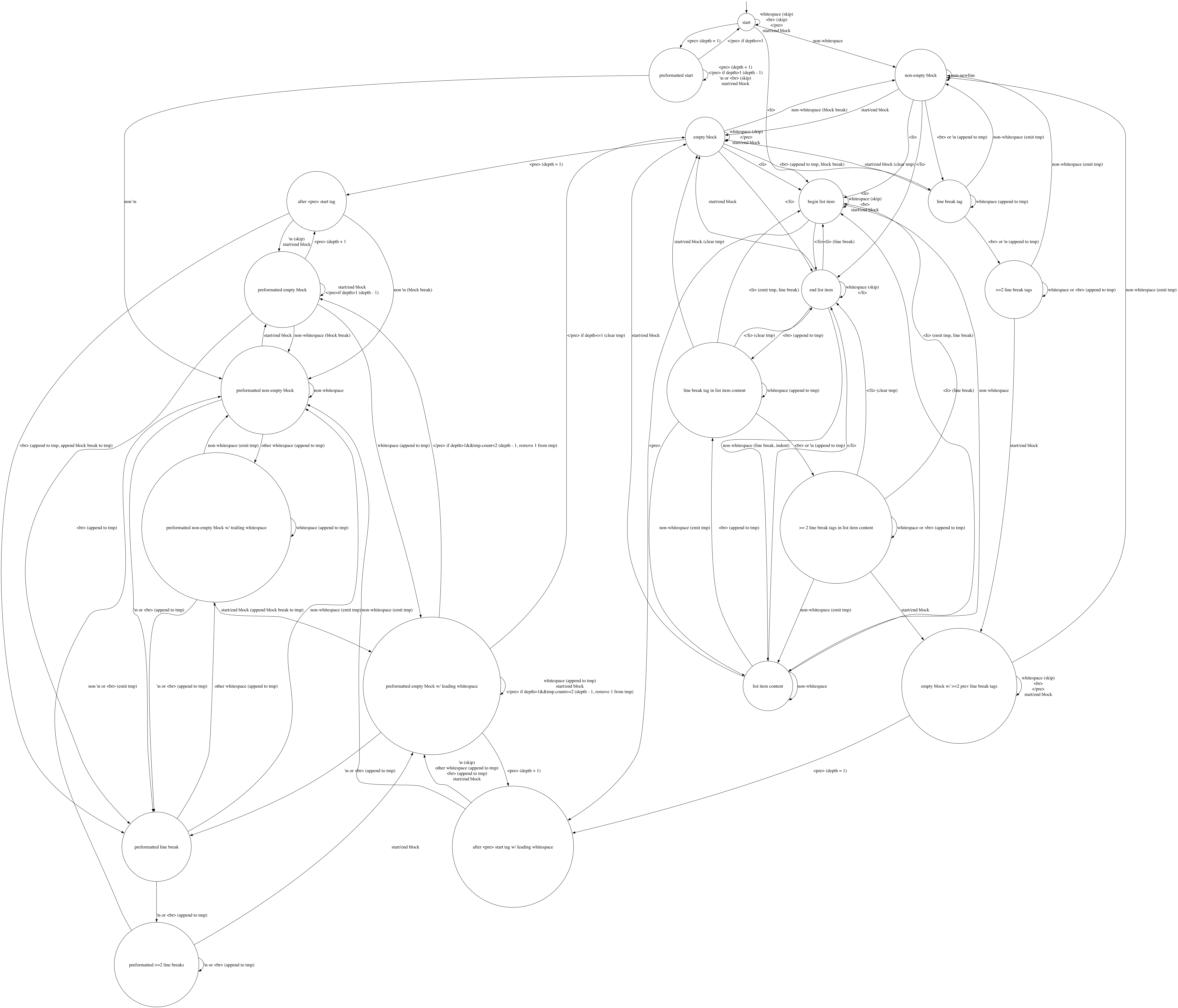
After trying to make my initial approach work for some time, while slowly discovering more and more of these edge cases, I gave up. Armed with the intuition that this feels like the sort of problem that should be tractable with a sufficiently complicated state machine, I spent a number of days drawing, abandoning, and redrawing diagrams in Freeform trying to cover all the inputs and properties I needed.
In addition to everything described above, the final version also covers a couple additional things such as nested <pre> tags (because why not) and removing (or preventing from being generated) leading/trailing whitespace from the output string.
With the diagram converted to code (and several intervening iterations of noticing issues and revising the diagram), I am left with a gnarly 600 lines of Swift consisting of 7 giant switch statements, each of which matches over the 20 distinct states of the machine.
The code by itself is nigh-impossible to reason about, which is why it bears the warning “This is not a place of honor. No highly esteeme—” er. I mean, which is why it bears the exhortation:
// DO NOT TOUCH THE CODE WITHOUT CHECKING/UPDATING THE DIAGRAM.
Speaking of the diagram: in an effort to preserve the sanity of future-me, I turned my chicken-scratch drawing into a GraphViz file that I could stick in version control. Here’s the rendered graph, in all its splendor (please write in with suggestions about how to make this not look like GraphViz is questioning its life choices):
Conclusion
In writing this blog post I ran into 1 2 more edge cases that I had not handled correctly.
While I don’t regret rewriting the HTML parsing/conversion code I had before, it does feel rather like having opened Pandora’s box.
And back to what I alluded to at the beginning, all this extra bookkeeping means the end-to-end HTML → attributed string conversion performance is now merely 2.3× faster than the old SwiftSoup-based implemention (as opposed to 2.7× faster before this whole state machine adventure).
Comments
Reply to this post via the Fediverse.